网络模拟简介
这篇文章介绍一下网络模拟相关的Linux工具,可以用于测试在不同网络环境下的协议工作情况。例如,不同延迟、不同带宽、不同的网络丢包率等等。主要借助Linux的 Network Namespace 以及 veth pair 和 TC 工具。【文章用到命令的总结在文章最后,点击这里 快速跳转】
一、真实网络是如何工作的(概念概览)
在开始做网络模拟之前,我们首先了解一下要模拟的对象 —— 真实网络是如何工作的,也就是 真实世界里的网络,到底是怎样一步步把你的数据从一台主机送到另一台主机的?
想象一下,你坐在电脑前打开浏览器,准备访问某个网站。你敲下网址的那一刻,系统内部随即启动了一整套“结构化的信息传输流程”:应用生成数据、操作系统封装数据、网络接口转换数据为电信号并发送、网络设备逐跳转发…… 这些步骤环环相扣,最终实现你的数据从本地计算机精确抵达远方的另一台设备。为了理解 Network Namespace、veth、TC 等虚拟化技术模拟的是什么,我们需要先依照数据流经过的顺序,将网络协议栈的核心组件串联起来。
-
Socket 通信接口
网络通信的故事从应用层开始。无论是浏览器、游戏客户端,还是某个服务进程,它们都希望将数据发送到网络中,而它们与操作系统网络协议栈交互的入口,就是 Socket。可以把 Socket 看作应用程序与网络协议栈之间的“通信接口抽象”。应用程序只需要通过 Socket 提交要发送的数据、接收外来的数据,而不必关心数据在操作系统内部如何被封装、路由、分片、重传等细节。换句话说,应用程序只需要关注“发送什么”,至于“如何在复杂的网络上正确送达”,都由 Socket 背后的协议栈负责。 -
IP 地址与 NIC 接口
Socket 把数据交出去之后,协议栈接手处理。首先,主机需要明确自己的身份和出口。操作系统会为每个网络接口(NIC)配置一个 IP 地址,这就像在城市中给每栋大楼分配门牌号,告诉外界这台主机在网络这个大城市中的具体位置。而 NIC (Network Interface Card) 就像大楼与外部世界通信的“总大门”,无论你用的是以太网还是 Wi-Fi,所有数据离开设备时都必须经过这个物理接口,它负责把数据转换为可以在外部世界传输的物理信号。 -
路由表(Routing Table)
当数据包被打上源 IP 和目的 IP 的标签后,信件已经准备出门,但它到底应该往哪条路走?这就轮到 路由表 出场了。路由表决定了数据包的去向:对于某个目的地的信件,是直接发给局域网内的邻居,还是应该交给“默认网关”(路由器)帮忙转送?主机必须依据这张表来决定每一个数据包的下一跳(Next Hop)是谁。 -
ARP 与 MAC 地址
一旦路由表确定了下一跳的 IP 地址,还有一个关键问题:网线和交换机并不认识 IP 地址,它们只认链路层的 MAC 地址。MAC 地址是硬件的物理标识。为了把下一跳的 IP 地址转换成对应的 MAC 地址,主机需要使用 ARP 协议(地址解析协议)在局域网内广播询问:“谁是这个 IP?你的 MAC 是多少?”。系统会将获取到的结果缓存在 ARP 表 中。有了 MAC 地址,数据包才能真正被封装成以太网帧。 -
物理传输与闭环
当链路层地址(MAC)就绪,NIC 便会把数据帧转换成电信号或无线波,送往外部世界。数据途中可能穿过交换机、路由器,最终到达目标的 NIC。随后,数据在目标主机内部通过校验,剥离 MAC 头、IP 头,层层向上,一直到达对方主机的 Socket。对方的应用程序通过它的 Socket 接收到数据,至此完成一个通信闭环。 在整个过程中,Socket 是入口,IP 确立身份,路由决定方向,ARP 解决物理寻址,NIC 负责最后的物理传输。理解了这个真实的链路流程,接下来介绍的 Linux 网络模拟工具,实际上就是在虚拟环境中复刻或修改上述的某一个环节。 -
真实链路的物理约束(链路质量)
最后,我们必须认识到真实物理链路并非理想的真空管道。当数据被 NIC 转化为物理信号投身于复杂的网络环境时,它立刻就会面临物理法则的约束与环境的挑战。带宽限制决定了单位时间内只能通过有限的数据量,就像高速公路的车道数限制了车流量;传播延迟是客观存在的,无论光速多快,跨越物理距离都需要时间;电磁干扰、信号衰减或物理遮挡会导致数据包在途中意外丢失;而当网络繁忙时,路由器内部的缓冲区可能溢出,导致数据被迫排队等待,从而引发延迟的剧烈抖动。这些带宽限制、传输延迟、随机丢包以及拥塞排队,共同构成了真实网络不可忽视的“链路质量”特征,也是网络协议在实际运行中必须面对的残酷现实。
二、虚拟世界与真实世界的对应关系
理解了真实网络的流转过程后,我们就能清晰地看到 Linux 网络模拟工具在其中扮演的角色。实际上,这些工具并非凭空创造新的概念,而是对上述真实组件的软件化复刻。
-
独立的协议栈容器:Network Namespace
在真实世界中,每一台物理主机都独享一套完整的网络环境。而在Linux模拟中,物理主机的角色可以由Network Namespace[netns]扮演。当你创建一个新的netns时,内核实际上是为你隔离出了一份独立的网络协议栈副本。这意味着,每个netns内部都有自己独立的Socket接口、IP地址空间、路由表以及ARP缓存表。在这个隔离的空间内,进程感觉自己就像运行在一台单独的计算机上,拥有完全属于自己的网络身份,这为模拟多节点的网络拓扑提供了基础。 -
虚拟网线与网卡:veth pair
有了独立的主机[netns],它们之间自然需要线路相连。在真实网络中,我们依靠网卡(NIC)和双绞线、光纤等来连接不同主机。在模拟环境中,veth pair完美替代了这两个组件。veth pair总是成对出现的,你可以把它想象成一根两端都自带了虚拟网卡的“虚拟网线”。我们将 veth pair 的一端插入一个 netns,另一端插入另一个 netns 或宿主机,就相当于用网线把两台设备连通了。数据包从一端的虚拟网卡发出,会直接通过内核内存复制,瞬间出现在另一端的虚拟网卡上,从而实现了链路层的连接。 -
模拟物理环境的物理特性:TC
虽然 veth pair 打通了连接,但它有一个缺点:它太完美了。由于它是基于内存复制的,传输几乎没有延迟,带宽也无穷大,且不会丢包。这与充满拥塞和噪声的真实物理网络大相径庭。这时就需要 TC (Traffic Control) 出场了。TC 工作在虚拟网卡的出入口[主要是出口],它负责模拟物理世界的网络质量。通过配置TC规则,我们可以人为地拦截流经veth的数据包,让它们排队等待以产生延迟,或者按比例随机丢弃以模拟信号干扰,甚至限制发送速率来模拟带宽瓶颈。TC让完美的虚拟线路变得真实且不完美,从而让我们能测试协议在恶劣环境下的表现。
三、Network namespace 基本用法
首先,我们来说明如何创造一个虚拟的主机,Linux 的 ip 命令套件提供了专门的 netns 子命令来管理网络命名空间。首先,我们可以尝试创建一个名为 ns1 的命名空间,这一步操作相当于在当前的 Linux 系统中开辟了一台逻辑上完全独立的虚拟主机。创建完成后,通过 list 命令可以列出当前系统中存在的所有命名空间,以验证操作是否成功。相关的命令如下所示:
# 创建一个名为 ns1 的命名空间
sudo ip netns add ns1
# 查看系统中所有的命名空间
sudo ip netns list创建命名空间只是第一步,更核心的操作是如何在这个隔离的环境中运行命令。Linux 为我们提供了 ip netns exec 命令来实现这一点。使用 ip netns exec 紧跟命名空间名称和具体要执行的指令,就能穿透进这个虚拟空间。例如,我们可以查看 ns1 内部的网络接口配置。你会发现,新创建的命名空间默认非常纯净,只包含一个回环接口(loopback device),且该接口默认处于关闭(DOWN)状态。因此,初始化环境的标准动作通常是将这个回环接口启动,以确保本地基础通信功能的正常。当模拟实验结束,或者不再需要这个虚拟环境时,应当将其删除以释放资源。只需要指定要清理的命名空间名称即可,系统会自动移除该命名空间及其内部所有的网络配置。
# 在 ns1 中执行 ip link 命令查看接口状态
sudo ip netns exec ns1 ip link
# 将 ns1 中的回环接口 lo 启动
sudo ip netns exec ns1 ip link set lo up
# 再次查看,可以看到 lo 已经变为 UNKNOWN 或 UP 状态
sudo ip netns exec ns1 ip link
# 删除名为 ns1 的命名空间
sudo ip netns del ns1四、Veth Pair 基本用法
我们通过上面的学习已经掌握了如何创建独立的网络命名空间,下一步就是将它与外部世界或者其他命名空间连接起来。Veth Pair(Virtual Ethernet Pair)就是 Linux 提供的虚拟网线。它总是成对出现,就像一根线的两头,数据从一头进去,会立刻从另一头出来。在默认情况下,创建出来的 Veth Pair 两端都在宿主机的网络空间中。为了构建连接,我们需要将这根网线的一头插在宿主机(或一个命名空间),将另一头插到目标命名空间。 物理连接建立后,还需要进行逻辑配置。就像给真实的网卡配置网络一样,我们需要分别给 Veth Pair 的两端配置 IP 地址,并启动接口。通常我们将两端配置在同一个网段内,以便它们可以直接通信。配置完成后,宿主机和命名空间之间就建立了一条通过内核内存转发的高速虚拟链路,可以通过 Ping 命令验证连通性。
特别注意:Docker 环境下的防火墙干扰
在部署本实验环境时,请务必检查宿主机是否安装了Docker。Docker 守护进程启动时,出于安全隔离的考虑,会默认修改宿主机的 iptables 防火墙规则,将流量转发链 (FORWARD Chain) 的默认策略设置为 DROP (丢弃)。这会导致一个非常典型的现象:虚拟网络构建成功后,网桥和路由表看起来都正常,IP 转发功能也已开启 (ip_forward=1),但虚拟节点之间无法跨网段通信。
# 如果遇到上述情况,请按照以下步骤排查和解决:
# 1. 排查方法
# 执行下面的命令,查看当前防火墙的转发策略:
# 如果输出结果中包含 Chain FORWARD (policy DROP),说明防火墙正在拦截你的实验流量。
sudo iptables -L FORWARD -n -v
# 2. 解决办法 执行以下命令,将转发策略修改为“允许” (Accept):
sudo iptables -P FORWARD ACCEPT
# 执行后再次测试连通性即可恢复正常。
# 注意:重启 Docker 服务或宿主机后,该策略可能会被 Docker 重置,需重新执行上述命令。4.1 【基础篇】虚拟网线直连:点对点通信模型
万事开头难,为了快速入门,我们首先在下面给出一个最简单的虚拟网络模型,点对点通信模型。
# 0. 准备工作:创建一个名为 ns1 的命名空间,相当于创建了一个虚拟主机
sudo ip netns add ns1
# 1. 创建一对 Veth Pair 接口 (网线,成对出现,分别插在两个主机上)
# 我们将这对网线的两个接口分别命名为 veth0 和 veth1。
# 此时,这两个接口都默认位于宿主机的网络空间中。
sudo ip link add veth0 type veth peer name veth1
# 2. 将一端移动到命名空间中
# 我们保留 veth0 在宿主机,将 veth1 移动到 ns1 命名空间中。
# 这相当于把网线的一头插进了 ns1 这台“虚拟主机”,veth0 默认插在宿主机。
sudo ip link set veth1 netns ns1
# 3. 配置宿主机一侧(veth0)
# 给宿主机的 veth0 接口配置 IP 地址(例如 10.0.0.1/24)并启动接口。
sudo ip addr add 10.0.0.1/24 dev veth0
sudo ip link set veth0 up
# 4. 配置命名空间一侧(veth1)
# 使用 ip netns exec 进入 ns1,给 veth1 配置同网段的 IP 地址并启动接口。
# 注意:必须同时启动回环接口 lo,否则某些通信可能会受阻。
sudo ip netns exec ns1 ip addr add 10.0.0.2/24 dev veth1
sudo ip netns exec ns1 ip link set veth1 up
sudo ip netns exec ns1 ip link set lo up
# 5. 验证连通性
# 现在链路已经通了。我们在宿主机上 ping 命名空间里的 IP (10.0.0.2)。
# 如果收到回复,说明虚拟网络构建成功。
ping -c 3 10.0.0.2
# 6. 清理环境
# 删除 Veth Pair 的任意一端(如 veth0),另一端也会随之自动删除。
# 或者直接删除命名空间 ns1,内部的 veth1 也会被自动清理。
sudo ip link delete veth0
sudo ip netns del ns1虚拟网络通信原理的简单解析
-
第 3、4 步配置的两个 IP 须在同一子网才行。这是因为 Veth Pair 仅提供了链路层的直连通道。根据 TCP/IP 协议,不同网段的主机通信属于 网络层行为,必须依赖路由器或网关进行转发。由于上述命令尚未配置任何路由转发规则,若强行设置为不同网段,宿主机将无法通过 ARP 获取目标 MAC 地址,导致 Network is unreachable 错误。跨网段组网将在下文演示。
-
在执行 ping 命令之前,我们通过脚本完成了一系列精细的网络构建工作。 首先,我们创建了一对 Veth Pair 模拟物理网线,并将一端(veth1)隔离进命名空间 ns1,相当于给这台虚拟主机插上了网卡,建立了一条跨越命名空间的物理通道。 其次,当执行 ip addr add 并 set up 接口时,Linux 内核会自动检测到网卡状态的变化,并立即在路由表中添加一条直连路由。
- 宿主机端:内核自动添加规则 [10.0.0.0/24 dev veth0 scope link]。意思是去往 10.0.0.x 网段的数据直接走 veth0 口,不需要网关。【可通过 ip route 查看主机静态路由表信息】
- ns1 端:同理,ns1 内部也会生成一条指向 veth1 的直连路由。
-
当环境就绪,你在宿主机执行 ping 10.0.0.2 时,数据流转过程如下:
-
路由决策 Linux内核接管Ping请求并查阅宿主机的路由表。内核匹配到刚才自动生成的直连路由规则,确认目标IP 10.0.0.2在veth0接口的直连网段,无需经过网关,直接由veth0发送。
-
地址解析 内核准备封装数据包,但发现缺少目标 MAC 地址。veth0 随即发送 ARP广播请求,询问[谁是10.0.0.2?],由于 Veth Pair 的连通性,广播包瞬间穿过虚拟网线到达 ns1 内的 veth1。ns1 确认身份后,以单播形式返回包含自身 MAC 地址的 ARP响应。【ARP详解】
-
请求发送 宿主机获得 MAC 地址后,构建ICMP回显请求报文。数据包源地址为 10.0.0.1,目的地址为 10.0.0.2。以太网帧从 veth0 通过虚拟网线传输至 veth1。
-
目标处理 ns1 的网络协议栈接收到数据包,校验无误后识别为 Ping 请求。内核立即生成对应的 ICMP回显应答报文**,此时源地址变为 10.0.0.2,目的地址指向宿主机 10.0.0.1。
-
应答返回 应答包沿着虚拟网线原路返回,从 veth1 传回宿主机的 veth0。宿主机收到应答,计算往返时间(RTT),最终在终端输出 64 bytes from 10.0.0.2…,标志着通信成功。
-
-
上述过程的简单图示如下:
[ 宿主机 Host ] [ 虚拟空间 ns1 ]
(相当于电脑或路由器) (相当于另一台设备)
| ^
| (1) 查表:去 veth0 | | (3) 收到请求
v v 发送回复
+-------+ +-------+
| veth0 | ============================= | veth1 |
+-------+ (2) 通过虚拟网线 veth pair +-------+
IP: 10.0.0.1 IP: 10.0.0.2
4.2【进阶篇】虚拟路由器组网:星型拓扑模型
通过刚才【基础篇】的最简单网络模拟,我们已经简单熟悉了 “虚拟主机,虚拟网线” 等虚拟设备的用法,但是在真实的网络模拟实验中,不可能只使用这么简单的网络拓扑,在下面的脚本中,我们不再满足于简单的点对点“网线直连”,而是构建了一个更复杂的星型网络架构。我们将宿主机模拟为一个拥有 3 个 LAN 口的多功能核心路由器,分别连接 3 个独立的网段,这 3 个网段中共有 4 台虚拟主机 Host1 ~ Host4。他们的网络拓扑图如下图:
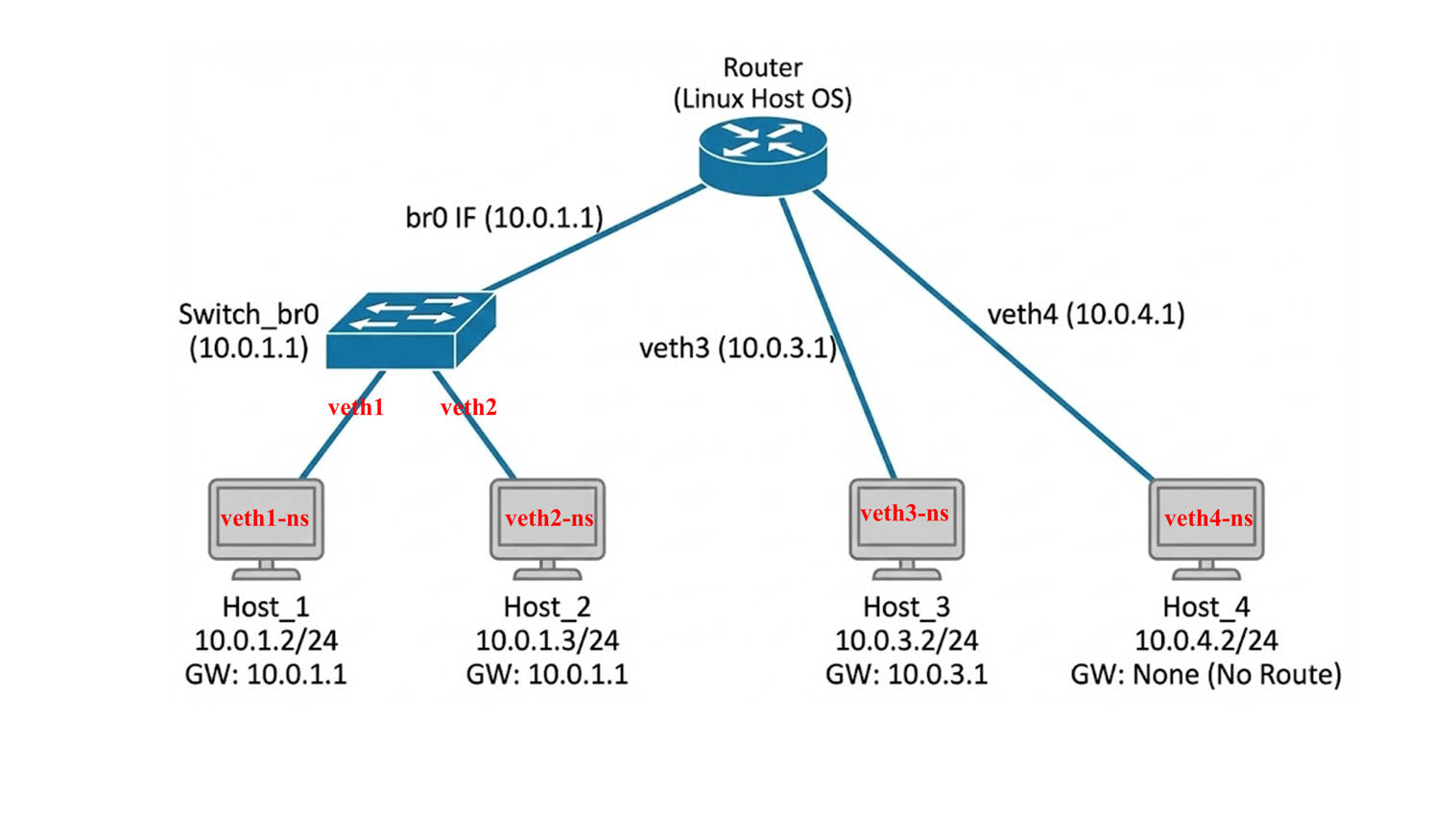
这并不是简单的重复连接。为了深入理解网络通信的底层逻辑,我们在宿主机内部特意设计了三种完全不同的连接模式(混合了交换机与路由器功能),旨在通过一次实验验证三个核心网络场景:
-
同网段二层交换
我们将 Host1 和 Host2 连接到同一个虚拟网桥 (br0) 上,并将它们配置在同一个网段 (10.0.1.x)。这旨在模拟“局域网内部通信”的场景,验证在不需要宿主机路由介入的情况下,设备之间是否可以通过 ARP 协议和 MAC 地址实现高速直连互通。 -
跨网段三层路由
Host3 位于一个独立的网段 (10.0.3.x),并且我们在其内部配置了正确的网关指向宿主机。这旨在模拟“访问外部网络”的场景,验证宿主机在开启转发功能后,能否成功扮演路由器的角色,将数据包在不同网段之间进行转发(观察 TTL 的变化)。 -
路由缺失导致的隔离
Host4 虽然在物理上通过 veth pair 连接到了宿主机,但我们特意不给它配置默认网关。这旨在模拟“配置错误的孤岛”场景,验证在物理连接正常但逻辑路由缺失的情况下,数据包为何无法走出自己的子网(出现 Network is unreachable 错误)。
#!/bin/bash
# ==========================================
# 0. 核心准备:启用内核转发 & 创建虚拟交换机
# ==========================================
# 开启 IP Forwarding,让宿主机具备路由器功能 (处理 Host3 <-> Host1/2 的流量)
sysctl -w net.ipv4.ip_forward=1 > /dev/null
# 创建一个网桥 br0,相当于在宿主机里放了一台“交换机”,并设置它的 ip
# Host1 和 Host2 都会连接到这个交换机上,实现同网段二层互通
ip link add name br0 type bridge
ip addr add 10.0.1.1/24 dev br0
ip link set br0 up
# ==========================================
# 1. 构建 Host1 & Host2 (同网段: 10.0.1.0/24)
# ==========================================
# [Host1]
ip netns add Host1
ip link add veth1 type veth peer name veth1-ns
# 将 veth1 一端插在 br0 (交换机) 上,而不是直接配 IP
ip link set veth1 master br0
ip link set veth1 up
# 将与 veth1 配对的网线另一头 veth-ns 插到 Host1 主机上,并设置 Host1 的 ip
ip link set veth1-ns netns Host1
ip netns exec Host1 ip addr add 10.0.1.2/24 dev veth1-ns
ip netns exec Host1 ip link set veth1-ns up
ip netns exec Host1 ip link set lo up
# 设置 Host1 的网关指向 br0 的地址 (10.0.1.1)
ip netns exec Host1 ip route add default via 10.0.1.1
# [Host2]
ip netns add Host2
ip link add veth2 type veth peer name veth2-ns
# 将 veth2 也插在同一个 br0 (交换机) 上,网关也指向 br0 的地址 (10.0.1.1)
ip link set veth2 master br0
ip link set veth2 up
ip link set veth2-ns netns Host2
ip netns exec Host2 ip addr add 10.0.1.3/24 dev veth2-ns
ip netns exec Host2 ip link set veth2-ns up
ip netns exec Host2 ip link set lo up
ip netns exec Host2 ip route add default via 10.0.1.1
# ==========================================
# 2. 构建 Host3 (独立网段: 10.0.3.0/24)
# ==========================================
# Host3 是另一个独立网段,通过宿主机路由与 Host1/2 通讯
ip netns add Host3
ip link add veth3 type veth peer name veth3-ns
# 宿主机端配置作为网关,地址设置为 10.0.3.1/24
ip link set veth3 up
ip addr add 10.0.3.1/24 dev veth3
# NS 端的配置,以及默认路由的设置
ip link set veth3-ns netns Host3
ip netns exec Host3 ip addr add 10.0.3.2/24 dev veth3-ns
ip netns exec Host3 ip link set veth3-ns up
ip netns exec Host3 ip link set lo up
ip netns exec Host3 ip route add default via 10.0.3.1
# ==========================================
# 3. 构建 Host4 (孤立网段: 10.0.4.0/24)
# ==========================================
# Host4 虽然有物理连接,但我们模拟“没有路由器”的场景
# 方法是:只给它配 IP,但【不给它配置网关 (default route)】
ip netns add Host4
ip link add veth4 type veth peer name veth4-ns
# 宿主机端配置
ip link set veth4 up
ip addr add 10.0.4.1/24 dev veth4
# NS 端配置:注意!这里只有 IP,没有 route add default
# 这意味着 Host4 只能和直连的 10.0.4.1 通话,不知道怎么去其他网段
ip link set veth4-ns netns Host4
ip netns exec Host4 ip addr add 10.0.4.2/24 dev veth4-ns
ip netns exec Host4 ip link set veth4-ns up
ip netns exec Host4 ip link set lo up
echo "网络构建完成。"虚拟网络通信原理的简单解析
-
网桥的概念与作用
在之前的实验中我们引入了一个名为 br0 的设备,它的学名叫做网桥[Bridge]。可以将其理解为宿主机内部的一个虚拟交换机。它工作在网络模型第二层的数据链路层。网桥的主要功能是根据 MAC 地址来转发数据帧,它并不关心数据包中的 IP 地址。当多个网络接口连接到同一个网桥上时,这些接口就相当于连接到了同一个交换机上。在本实验中,Host1 和 Host2 的网线都插在了 br0 上,在逻辑上组成了一个局域网,不需要经过路由器就能直接进行通信。
此外,Linux 网桥还有一个特殊的“双重身份”:它不仅是交换机,其自身(即同名的 br0 接口)也是宿主机直接接入该网络的一个虚拟网卡。这意味着宿主机无需通过额外的 Veth 线连接网桥,在配置了 br0 接口的 IP 后,它就自动作为宿主机的一个网卡。 -
Veth Pair 的初始位置与迁移
在创建 Veth Pair 的过程中,有一个细节非常重要。当我们执行 ip link add 命令创建一对虚拟网线时,这两个网线头(例如 veth1 和 veth1-ns)最初默认都是诞生在宿主机的网络命名空间中的[插在了宿主机上]。就像是一根卷在宿主机地板上的网线,两头都在宿主机手里。只有当我们执行后续的 ip link set netns 命令时,才是真正将其中一端拿起来,穿过隔离墙,放入指定的命名空间(如 Host1)中。这一步操作完成了从宿主机到命名空间的跨界物理连接。
我们将通过三个具体的场景来验证不同的网络通信模式。
场景一:同网段二层互通 (Host1 -> Host2)。
我们将尝试从 Host1 ping Host2。这两台主机都连接在网桥 br0 上,且 IP 地址位于同一个 10.0.1.0/24 网段。我们执行以下命令进行测试:
# 1. 让 Host1 (10.0.1.2) 去 ping 同网段的 Host2 (10.0.1.3)
sudo ip netns exec Host1 ping -c 3 10.0.1.3
# 2. 预期输出结果:
PING 10.0.1.3 (10.0.1.3) 56(84) bytes of data.
64 bytes from 10.0.1.3: icmp_seq=1 ttl=64 time=0.045 ms
64 bytes from 10.0.1.3: icmp_seq=2 ttl=64 time=0.056 ms
64 bytes from 10.0.1.3: icmp_seq=3 ttl=64 time=0.052 ms
# 3. 结果分析:
# 原理:数据链路层的二层交换。
# 当 Host1 发送数据时,网桥 br0 检测到目标 MAC 地址位于同一链路的另一个端口,直接进行转发。
# 重点观察:ttl=64。
# TTL (Time To Live) 是数据包的生存时间,每经过一个路由器(网关)就会减 1。
# 这里 TTL 保持为初始值 64 没有减少,证明数据包根本没有经过路由层,
# 就像两个人面对面传纸条,没有经过中间人转交,这是一次纯粹的二层直连通信。当我们执行 ping 10.0.1.3 时; 通信成功,TTL=64。此时数据通讯过程如下:
-
路由决策
在 Host1 中运行 ping 命令之后,Host1 的内核接管 Ping 请求。它查阅自身的路由表,发现目标 IP 10.0.1.3 位于 10.0.1.0/24 网段。由于 Host1 的 IP 也是 10.0.1.2,内核判断目标在同一网段(On-link),因此无需查找网关,决定直接向目标发起连接。 -
地址解析
内核准备封装数据包,但缺少目标 MAC 地址。Host1 发送 ARP 广播:“谁是 10.0.1.3?”。这个广播包进入宿主机的虚拟交换机 br0。br0 将广播包泛洪给所有连接的端口。Host2 收到广播后,确认是在找自己,于是单播回复自己的 MAC 地址。 -
数据转发 (网桥介入)
Host1 拿到 MAC 地址后,构建 ICMP 请求包并发出。- Host1 动作:数据包源MAC是Host1,目标MAC是Host2。数据包离开Host1进入网桥 br0。
- 网桥动作:br0 收到数据包后,查阅自己的MAC地址表(FDB),它发现目标 MAC (Host2) 对应的是接口 veth2。然后网桥完全不修改数据包内容,直接将数据包搬运到 veth2 接口。
-
目标处理与返回
Host2 收到包,生成 ICMP 应答。应答包同样通过 br0 查表后,直接交换回 Host1。整个过程数据包仅在链路层流转,因此 TTL 值保持 64 不变。
场景二:跨网段三层路由 (Host1 -> Host3):
我们将尝试从 Host1 ping Host3。Host1 位于 10.0.1.0/24 网段,而 Host3 位于 10.0.3.0/24 网段,中间通过宿主机作为路由器连接。
# 1. 让 Host1 (10.0.1.2) 去 ping 不同网段的 Host3 (10.0.3.2)
sudo ip netns exec Host1 ping -c 3 10.0.3.2
# 2. 预期输出结果:
PING 10.0.3.2 (10.0.3.2) 56(84) bytes of data.
64 bytes from 10.0.3.2: icmp_seq=1 ttl=63 time=0.067 ms
64 bytes from 10.0.3.2: icmp_seq=2 ttl=63 time=0.071 ms
64 bytes from 10.0.3.2: icmp_seq=3 ttl=63 time=0.069 ms
# 3. 结果分析:
# 原理:网络层的三层路由转发。
# Host1 发现目标 IP 不在本地,将包发给默认网关(宿主机)。
# 宿主机查表后,将包从 br0 接口路由转发到 veth3 接口。
# 重点观察:ttl=63。
# 这里的 TTL 从默认的 64 变成了 63。这减去的 1 就是宿主机作为路由器扣除的“过路费”。
# 只要看到 TTL 减少了,就铁证如山地说明数据包经过了路由器的转发处理。当我们执行 ping 10.0.3.2 时; 通信成功,TTL=63。此时数据通讯过程如下:
-
源端路由决策
当 Host1 执行 ping 后,Host1 查阅路由表,发现目标 10.0.3.2 并不在本地网段。内核匹配到默认路由规则 default via 10.0.1.1,决定将数据包托付给默认网关(即宿主机的 br0 接口)。 -
第一程传输 (Host1 到 宿主机)
Host1 构建数据包。注意此时的 MAC 地址变化:源 MAC 是 Host1,但在链路层封装时,目标 MAC 填的是网关 br0 的 MAC 地址。数据包到达 br0 后,网桥发现这是发给宿主机自己的数据包(即发给网关地址),于是将其从链路层上交给宿主机的内核网络栈。 -
核心路由转发 (宿主机介入)
宿主机内核拆开数据包,检查 IP 头部发现目标 IP 10.0.3.2 不是自己,而是连接在另一只手 veth3 上的设备。由于开启了 ip_forward,内核执行标准的三层转发操作:首先查询路由表找到出口 veth3,然后将数据包的 TTL 减 1(变为 63),并将 源 MAC 修改为 veth3 的 MAC,目标 MAC 修改为 Host3 的 MAC,修改后的数据包从宿主机的 veth3 接口发到 Host3。 -
第二程传输与返回
Host3 收到后生成应答包。由于 Host3 也要跨网段回复,它同样会把宿主机当做网关,应答包按原路被宿主机路由转发回去。中间的过程和上述步骤相似,这里不再赘述。
场景三:路由缺失导致的隔离 (Host4 -> Host1)。
我们将尝试从 Host4 ping Host1。Host4 虽然物理上连接了宿主机,IP 配置也正确,但我们在脚本中故意没有给它配置默认网关。
# 1. 让 Host4 (10.0.4.2) 尝试 ping Host1 (10.0.1.2)
sudo ip netns exec Host4 ping -c 3 10.0.1.2
# 2. 预期输出结果(直接报错):
# ping: connect: Network is unreachable
# 3. 进一步验证(查看路由表):
sudo ip netns exec Host4 ip route
# 输出:
10.0.4.0/24 dev veth4-ns proto kernel scope link src 10.0.4.2
# (注意:这里缺少了 default via ... 的默认路由记录)
# 如果执行 sudo ip netns exec Host3 ip route,那么输出时:
# default via 10.0.3.1 dev veth3-ns [有默认路由]
# 10.0.3.0/24 dev veth3-ns proto kernel scope link src 10.0.3.2
# 4. 结果分析:
# 原理:路由表缺失导致路径不可达。
# 尽管物理连接是通畅的,但 Host4 的路由表中只有自己门口(10.0.4.0/24)的地图。
# 当它想去 10.0.1.2 时,发现既没有直连路由,也没有默认网关指出“出口”在哪里。
# 内核不知道该把数据包交给谁,因此直接在本地拒绝了请求。
# 这证明了在三层网络中,物理连通不等于逻辑连通,正确的路由配置是通信的必要条件。当我们执行 ping 10.0.1.2 时;立即报错 Network is unreachable。此时数据通讯过程如下:
-
路由决策 (Host4 内核)
在 Host4 执行 ping 10.0.1.2 时,Host4 的内核接管 Ping 请求,准备发送数据给 10.0.1.2。它首先查阅自身的路由表,发现其中只有一行直连路由 10.0.4.0/24。这行规则只能匹配 10.0.4.x 的本地地址。对于目标 10.0.1.2,没有任何精确路由规则能匹配上。 -
兜底检查 (缺失)
在精确匹配失败后,内核通常会寻找 默认路由 (default gateway) 作为最后的希望。但是,我们在配置 Host4 时故意没有设置网关。这意味着 Host4 根本不知道如何走出自己的房间。 -
内核拒绝
内核发现“上天无路,入地无门”,不知道该把这个包交给谁(甚至无法发出 ARP 请求,因为不知道该问谁)。于是内核直接在本地终止操作,并向用户程序抛出 Network is unreachable 错误。这证明了在三层网络中,物理连接只是基础,路由配置才是通行的指南针。
实验结束后记得将创建的 netns 和 veth pair 全部销毁,下面给出一键清理命令。
# 查看当前的命名空间有什么虚拟主机
sudo ip netns list
# 一键删除所有网络命名空间:
# - ip netns list:列出当前系统中所有 netns
# - awk '{print $1}':取出 netns 名称(每行的第 1 列)
# - xargs -I {} ip netns delete {}:对每个 netns 名称执行删除
sudo ip netns list | awk '{print $1}' | xargs -I {} sudo ip netns delete {}
# 这里需要注意的是:删除 netns 会导致对应 veth pair 也自动删除?
# 这是因为 veth 是成对出现的虚拟接口(veth pair),一端在宿主机、另一端被移入 netns。
# 只要任意一端所属的 netns 被删除:
# → netns 内的那端 veth 会被内核销毁
# → veth 是成对的,因此宿主机的那一端也会随之被一并删除
# 所以:删除 netns = 相关 veth pair 也自动被删除
# 或者使用下面的命令可以查看当前系统中创建的 veth pair (假设所有veth pair命名中都含有 veth)
ip link | grep veth
# 如果有,可以使用以下命令一键删除【删除的是veth命名的】
ip -o link show | grep veth | awk -F': ' '{print $2}' | cut -d'@' -f1 | xargs -r -n1 sudo ip link delete
# 删除 br-swarm 可以用下面的公式
sudo ip link delete br-swarm4.3 【实战篇】构建网络服务:客户端/服务器(C/S)通信模型
在前两节中,我们验证了网络层(Layer 3)的连通性,即通过 Ping 命令证明了数据包可以在不同主机间传输。但在现实世界中,网络是为了应用服务的。在本节中,我们将跨越传输层(Layer 4)和应用层(Layer 7),在 Host3 上部署真实的网络服务,并让 Host1 作为客户端去访问它。这将验证我们的虚拟网络不仅能“通”,还能“跑业务”。
实验一:穿越路由的 TCP 聊天室 (基于 Netcat):
我们使用 nc (Netcat) 工具建立一个原始的 TCP 连接。Host3 作为服务端监听特定端口,Host1 作为客户端发起连接。连接建立后,双方可以像聊天室一样实时发送文本信息。这模拟了最基础的 Socket 通信过程。此时能够访问 Host3 的用户都能和他交互。
- 步骤 1:Host3 作为服务端启动 Netcat 监听 8888 端口,进入阻塞状态等待客户端的连接。
- 步骤 2:用新的终端窗口让 Host1 作为作为客户端 向 Host3 的 IP:8888 端口发起 TCP 连接。
- 接着,Host1 和 Host3 都可以在自己的窗口输入信息,另一个窗口会自动同步显示出来。
# 1. 首先,确保系统中拥有 nc,如果没有使用下列命令安装。
sudo apt install netcat-openbsd
# 2. 使用 nc 命令监听端口,使用到的参数如下:
# -l: 监听模式 (Listen)
# -v: 显示详细信息 (Verbose)
# -n: 不解析域名 (加快速度)
# -p: 指定端口 (Port)
sudo ip netns exec Host3 nc -lvnp 8888
# 3. 在新的窗口,让Host1 连接 Host3 的 IP (10.0.3.2:8888)
sudo ip netns exec Host1 nc -v 10.0.3.2 8888
# 4. 成功后,Host1 的终端会提示 Connection to 10.0.3.2 8888 port [tcp/*] succeeded!。
# 此时,你在 Host1 的终端输入任何字符并回车,Host3 的终端都会立刻显示出来;反之亦然。
# 这个实验证明了 Host1 和 Host3 之间成功完成了 TCP 三次握手。数据包不仅被宿主机(路由器)
# 正确转发,还被目标主机的操作系统准确地传递给了监听在 8888 端口的应用程序。实验二:自定义业务逻辑——平方计算服务器 (基于 Python)
Netcat 只是负责透传数据,没有处理逻辑。在这个实验中,我们将使用 Python 编写一个简单的 Socket 服务端程序。它的功能是:接收客户端发来的数字,计算它的平方值,然后将结果返回给客户端。这将模拟一个具备具体业务逻辑的应用服务器。
-
步骤 1:在宿主机编写一个 Python 脚本 (math_server.py),逻辑为:建立 TCP 监听 -> 接收数据 -> 转换为数字 -> 计算平方 -> 发回结果。
-
步骤 2:将该脚本运行在 Host3 的网络命名空间中,监听 9999 端口。
-
步骤 3:让 Host1 使用 Netcat 连接 Host3 的 9999 端口,发送数字并接收计算结果。
# 1. 首先,在宿主机上通过命令行快速创建一个名为 math_server.py 的脚本。
# (直接创建一个名为 math_server.py 的文件,复制以下所有代码并在终端运行)
# ------------------------- 以下为 math_server.py 的内容 ---------------------------
import socket
HOST = '0.0.0.0'
PORT = 9999
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
s.bind((HOST, PORT))
s.listen()
print(f"Host3 计算服务监听中: {PORT}...")
while True:
conn, addr = s.accept()
with conn:
print(f"连接来自: {addr}")
conn.sendall(b"Welcome! Enter a number:\n")
while True:
data = conn.recv(1024)
if not data: break
try:
input_str = data.decode().strip()
if not input_str: continue
num = float(input_str)
conn.sendall(f"Result: {num}^2 = {num*num}\n".encode())
except ValueError:
conn.sendall(b"Error: Not a number!\n")
# ------------------------- 以上为 math_server.py 的内容 ---------------------------
# 2. 启动服务端:将该脚本运行在 Host3 的网络命名空间中。
# 注意:这会占用当前终端窗口。
sudo ip netns exec Host3 python3 math_server.py
# 3. 在新的窗口,让 Host1 连接 Host3 的 9999 端口进行测试。
sudo ip netns exec Host1 nc 10.0.3.2 9999
# 4. 连接成功后,进行交互测试。
# 此时,你在 Host1 输入 "5" 并回车,Host3 的 Python 程序会计算并返回 "25.0"。
# 输入 "hello" 则会返回错误提示。
# 这个实验展示了网络编程的核心模型。Host1 发送的数据流经过网络传输到达 Host3,
# Host3 的内核将数据交给 Python 进程。Python 进程解析数据,执行 CPU 计算逻辑,
# 再将结果封装并通过网络发回。这正是现代互联网应用(如 Web 服务、数据库服务)工作的基本原型。4.4 【仿真篇】弱网环境模拟:TC (Traffic Control)
通过上述一系列循序渐进的实验,我们不仅掌握了如何使用 Linux 网络命名空间(Netns)构建复杂的虚拟网络拓扑,更深刻理解了从物理链路层(Veth Pair)、数据链路层(Bridge)到网络层(Routing)的通信基石。更重要的是,最后的实战章节向我们揭示了一个核心真理:网络架构是业务的载体,而业务逻辑是网络的灵魂。 只要底层的虚拟网络环境构建完毕,它就如同铺设好了的高速公路。我们只需要根据实际需求(无论是区块链节点通信、还是普通的 Web 服务等),编写相应的客户端和服务端代码(Socket/HTTP),就能在这张“网”上跑各种复杂的应用。
但是在前几节中,我们构建的虚拟网络环境是近乎完美的:链路稳定、延迟极低(通常 < 0.1ms)、没有丢包。然而,真实的网络环境(特别是广域网或移动网络)往往充满了不确定性。为了测试我们的应用程序在弱网环境下的表现(例如:测试 TCP 重传机制、验证分布式系统的超时逻辑),我们需要一种工具来模拟带宽限制、传输延迟和数据包丢失。Linux 内核自带的 TC (Traffic Control) 子系统配合 Netem (Network Emulator) 模块,正是为此而生。
TC简介:TC 工作在 Linux 内核的 出口流量处。可以把它想象成设置在网卡出口的一个收费站。所有要离开这张网卡的数据包,都必须先经过 TC 的处理。我们可以在这里让数据包排队(增加延迟)、限制通过的速度(限制带宽)、甚至扔掉一部分(模拟丢包)。TC 的核心是 qdisc,也就是排队规则 (Queueing Discipline),它决定了数据包如何被发送。我们将使用 root规则下的 netem 模块。在下面,我们分别给出几种常见网络环境的模拟。 我们将以 Host3 为例,对其出口接口 veth3-ns 施加影响。 (注意:TC 规则施加在哪个接口上,受影响的就是从该接口发出的流量。)
- 场景一:模拟网络高延迟 (Latency)
这是最常见的测试,用于模拟跨国传输或卫星链路。【瞎吹的,反正模拟高延迟】
# 什么都没做时,使用Host1 ping Host3,延迟大概为 time=0.xx ms
sudo ip netns exec Host1 ping 10.0.3.2
# 例子:给 Host3 增加 100ms 的固定延迟
# 命令语法:tc qdisc add dev [设备名] root netem delay [时长]
sudo ip netns exec Host3 tc qdisc add dev veth3-ns root netem delay 100ms
# 验证:此时从 Host1 ping Host3
# 结果:time=100.xx ms (原本是 0.0x ms)
sudo ip netns exec Host1 ping 10.0.3.2- 场景二:模拟网络抖动 (Jitter)
现实网络中延迟往往是不稳定的。抖动是指延迟时间的波动
# 例子:延迟 100ms,上下波动 20ms (即 80ms ~ 120ms 之间随机)
# 命令语法:tc qdisc [add/change] dev [设备名] root netem delay [基础时长] [波动范围]
# 注意:这里用了 change,如果你之前已经 add 过了,修改规则要用 change,或者先 del 再 add。
sudo ip netns exec Host3 tc qdisc change dev veth3-ns root netem delay 100ms 20ms
# 验证:此时从 Host1 ping Host3
# 结果:time=[100±20].xx ms (原本是 0.0x ms)
sudo ip netns exec Host1 ping 10.0.3.2- 场景三:模拟数据包丢失 (Packet Loss)
用于测试 TCP 的可靠传输能力或 UDP 的容错能力。
# 例子:随机丢弃 30% 的数据包 (非常恶劣的网络环境)
# 命令语法:tc qdisc change dev [设别名] root netem loss [百分比]
sudo ip netns exec Host3 tc qdisc change dev veth3-ns root netem loss 30%
# 验证:ping -c 10,你会发现大概只有 7 个包能收到。当然,会有波动,是随机的。
sudo ip netns exec Host1 ping -c 10 10.0.3.2- 场景四:模拟带宽限制 (Bandwidth Limit)
用于测试视频流的卡顿、大文件传输的速率限制或弱网环境下的加载时间。
# 虽然netem也能做简单的限速,但业界通常使用更准确的tbf算法[Token Bucket Filter 令牌桶]。
# 命令语法:tc qdisc change dev [设备名]
# root tbf rate [带宽] burst [缓冲区大小] latency [最大延迟]
# rate: 限制的速率 (如 1mbit, 500kbit)
# burst: 桶的大小/缓冲区
# 【允许瞬间突发的数据量,通常设为 10kb~32kb,太小会导致低速率下发包困难】
# latency: 也就是 limit,当令牌耗尽时,数据包在队列中等待的最长时间。
# 例子:将 Host3 的出口带宽限制在 1Mbit/s (约 125KB/s)
sudo ip netns exec Host3 tc qdisc change dev veth3-ns
root tbf rate 1mbit burst 32kbit latency 400ms
# --- 验证方法 ---
# 我们需要让 Host3 发送大量数据给 Host1,看看速度是不是被卡住了。
# 步骤 1: 在 Host1 (接收端) 开启一个空洞,只接收数据不存盘,避免硬盘读写影响测试
# -l: 监听, -p: 端口
sudo ip netns exec Host1 nc -l -p 8888 > /dev/null
# 步骤 2: 在 Host3 (发送端/被限速端) 用 dd 生成 5MB 数据并通过管道传给 Host1
# 注意:这里必须用 bash -c "..." 把整个命令包起来,
# 否则管道符 "|" 会被宿主机解释,而不是在 Host3 的命名空间内执行。
#
# if=/dev/zero: Input File,从系统零设备读取无限的空数据
# bs=1M: Block Size,每块大小为 1MB
# count=5: 读 5 次就停止 (即总共生成 5MB 数据)
# | nc ...: 将 dd 生成的数据流,通过管道直接灌入 nc 发送给目标
sudo ip netns exec Host3
bash -c "dd if=/dev/zero bs=1M count=5 | nc 10.0.1.2 8888"
# 预期输出:
# dd 命令执行完毕后会打印统计信息,你应该会看到类似下面的结果:
# 5242880 bytes (5.2 MB, 5.0 MiB) copied, 41.xxx s, 127 kB/s
#
# 结果分析:
# 1. 数据量:5MB 数据传输完毕。
# 2. 耗时:约 41 秒 (5MB * 8bit / 1Mbit ≈ 40秒)。
# 3. 速度:127 kB/s。这正好对应 1mbit (1000000 bits / 8 = 125000 bytes ≈ 125KB/s)。
# 证明限速完美生效。- 场景五:模拟包乱序 (Reordering)
用于模拟多路径路由或设备处理能力不稳定导致的数据包到达顺序错乱。这对于测试 TCP 的重排序能力(Reassembly)或实时视频流的抖动缓冲(Jitter Buffer)非常关键。
# 核心原理:
# Netem 的乱序机制其实是“部分包不延迟”。
# 我们设定一个基础延迟(比如 100ms),然后设定一定比例的包(比如 50%)为“乱序包”。
# 结果是:50% 的包会被延迟 100ms 发送,而那 50% 的包会“立即”发送。
# 这样一来,后发的“立即包”就会赶在先发的“延迟包”之前到达目的地,形成乱序。
# 命令语法:tc qdisc change dev [设备名]
# root netem delay [基础延迟] reorder [乱序比例] [相关性]
# 例子:设基础延迟 100ms,但有 50% 的包会立即发送,
# 相关性50%指:当前这个包是否乱序,很大程度上取决于前一个包的状态
# 如果第一个包运气不好,没有乱序(走了 100ms 延迟通道)。
# 那么第二个包有 50% 的概率会“模仿”前一个包(也不乱序)。
sudo ip netns exec Host3 tc qdisc change
dev veth3-ns root netem delay 100ms reorder 50% 50%
# --- 验证方法 ---
# 使用 ping 命令即可验证。
# 因为 ICMP 报文里有序列号 (icmp_seq)。正常情况下 seq 是 1, 2, 3, 4 递增。
# 如果发生乱序,我们会在接收端看到 seq 的打印顺序变乱。
# 注意:Ping 的速度必须够快!默认 Ping 每秒发一次。如果延迟只有 100ms,
# 前一个包早就到了,后一个包还没发,根本无法发生“插队”。
# 所以我们需要用 -i 参数将发包间隔缩短到 5ms (0.005s),让包在网络上“拥挤”起来。
sudo ip netns exec Host1 ping -c 20 -i 0.005 10.0.3.2
# 预期输出:
# 请仔细观察 icmp_seq 的数值顺序,你会发现它们不再是严格递增的。
#
# PING 10.0.3.2 (10.0.3.2) 56(84) bytes of data.
# 64 bytes from 10.0.3.2: icmp_seq=2 ttl=63 time=0.040 ms <-- seq=2 先到了!
# 64 bytes from 10.0.3.2: icmp_seq=1 ttl=63 time=100.1 ms <-- seq=1 后到了
# 64 bytes from 10.0.3.2: icmp_seq=4 ttl=63 time=0.035 ms <-- seq=4 插队了
# 64 bytes from 10.0.3.2: icmp_seq=3 ttl=63 time=100.2 ms <-- seq=3 姗姗来迟
#
# 结果分析:
# 1. 观察 seq:顺序变成了 2 -> 1 -> 4 -> 3。证明包到达顺序乱了。
# 2. 观察 time:乱序包(插队的)延迟极低 (~0.04ms),而正常包延迟在 10ms 左右。
# 这证明了 Netem 确实是通过“让一部分包不延迟”来实现乱序的。- 组合技:模拟真实的复杂弱网
在现实物理网络中,丢包、延迟和带宽限制往往是同时发生的。tc 允许我们将这些参数组合使用,从而构建高保真的弱网环境。下面我们介绍两中组合限制的案例,说明如何更真实的模拟真实网络环境。
案例 A :Netem 参数混合,模拟同时又延迟 + 抖动 + 丢包的情况
这是最简单的方式,直接在 netem 后面跟随多个指标,用于模拟信号干扰严重的环境。
# 核心原理:
# Netem 模块本身支持参数叠加。我们可以像搭积木一样,
# 在一行命令里同时指定延迟(Delay)、抖动(Jitter)和丢包率(Loss)。
# 这能模拟出类似“远距离无线传输”或“跨国链路”的不稳定状态。
# 命令语法:tc qdisc change ... netem delay [延迟] [抖动] loss [丢包率]
# 例子:模拟无人机远距离通信:
# 1. 基础延迟 100ms,上下抖动 20ms (80~120ms 之间波动)
# 2. 伴随 10% 的随机丢包
sudo ip netns exec Host3 tc qdisc change dev veth3-ns root netem \
delay 100ms 20ms loss 10%
# --- 验证方法 ---
# 使用 ping 命令观察延迟波动和丢包情况。
# -c 20: 发送 20 个包,样本足够看清丢包率。
sudo ip netns exec Host1 ping -c 20 10.0.3.2
# 预期输出:
# PING 10.0.3.2 (10.0.3.2) 56(84) bytes of data.
# 64 bytes from 10.0.3.2: icmp_seq=1 ttl=63 time=102 ms <-- 延迟 > 100ms
# 64 bytes from 10.0.3.2: icmp_seq=2 ttl=63 time=85.4 ms <-- 发生抖动 (变快)
# 64 bytes from 10.0.3.2: icmp_seq=3 ttl=63 time=118 ms <-- 发生抖动 (变慢)
# ... (中间可能缺失某个 seq) ... <-- 发生丢包
#
# --- 10.0.3.2 ping statistics ---
# 20 packets transmitted, 18 received, 10% packet loss, time 19032ms
#
# 结果分析:
# 1. Packet loss: 出现了约 10% 的丢包。
# 2. Time: 延迟不再是固定的,而是在 100ms 附近上下跳动。案例 B:限速 + 弱网 (高阶层级)
由于限速通常使用 tbf (令牌桶) 算法,而延迟丢包使用 netem 算法,同一个接口的根节点只能有一个算法。因此我们需要利用 TC 的树状层级结构 (Hierarchy) 将它们串联起来。
# 核心原理:父子级联 (Chaining)
# 我们构建一个处理流水线:
# 1. 第一关 (父节点 root):使用 TBF 算法限制带宽(把路变窄)。
# 2. 第二关 (子节点 parent):在 TBF 下面挂载 Netem 算法增加延迟(把路变长)。
# 数据包必须先通过限速,再经过延迟,才能发出去。
# 步骤 1: 设置限速 (父节点 handle 1:) [先删除原来的配置]
# rate 500kbit: 限制带宽为 500Kbps (约 62KB/s)
sudo ip netns exec Host3 tc qdisc del dev veth3-ns root 2>/dev/null
sudo ip netns exec Host3 tc qdisc change dev veth3-ns \
root handle 1: tbf rate 500kbit burst 16kbit latency 400ms
# 步骤 2: 挂载延迟 (子节点 parent 1:1)
# parent 1:1 : 表示挂载在 ID 为 1 的规则的第 1 个输出口上
# handle 10: : 给这个 Netem 规则起个 ID 叫 10
sudo ip netns exec Host3 tc qdisc add dev veth3-ns \
parent 1:1 handle 10: netem delay 100ms
# --- 验证方法 ---
# 这个实验需要验证两个指标:延迟 和 带宽。
# 验证 1: 测延迟 (Ping)
sudo ip netns exec Host1 ping -c 4 10.0.3.2
# 验证 2: 测带宽 (DD + NC)
# 开启接收端 (Host1)
sudo ip netns exec Host1 nc -l -p 8888 > /dev/null &
# 开启发送端 (Host3) 发送 5MB 数据
sudo ip netns exec Host3 bash -c "dd if=/dev/zero bs=1M count=5 | nc 10.0.1.2 8888"
# 预期输出:
# 1. Ping 的结果:
# time=100 ms 左右。 (证明 Netem 生效)
#
# 2. DD 的结果:【由于TCP的缓冲区问题,这个速度可能稍大于63.4kb/s】
# 5242880 bytes (5.2 MB, 5.0 MiB) copied, 80.xxx s, 63.4 kB/s
#
# 结果分析:
# 1. 速度被死死卡在 63.4 kB/s (即 500kbit / 8),证明父节点 TBF 生效。
# 2. Ping 延迟稳定在 100ms,证明子节点 Netem 生效。
# 3. 两者完美共存。- 综合案例:在"风暴"中通信 —— TCP 重传机制观测
在前一节中,我们编写了一个 Python 平方计算服务器。在网络良好的情况下,它响应迅速,计算精准。现在,让我们利用 tc 工具制造一场人为的“网络风暴”,模拟 50% 丢包率 的极端弱网环境,以此来亲身体验 TCP 协议的 可靠传输特性。这就好比我们将一辆车(Python 服务)开进了烂泥地(丢包网络),观察它的防滑系统(TCP 重传)是否工作正常。
# 1. 实验准备
# 确保 Host3 上的 Python 计算服务正在运行(参考 4.3 节),并在 Host1 上准备好终端。
# 可以现在这个窗口运行下面服务,然后加上 2. 中的延迟,也可以先加延迟在运行服务器。
sudo ip netns exec Host3 python3 math_server.py
# 2. 在 Host3 上设置 70% 的随机丢包,制造“网络风暴”
# root: 根队列规则
# netem: 网络仿真模块
# loss 70%: 丢包率 70%
# 如果已经添加了 veth3-ns 设备,下面使用 tc qdisc change dev veth3-ns
sudo ip netns exec Host3 tc qdisc add dev veth3-ns root netem loss 70%
# 3. 艰难的“握手” (Host1)
# 现在,尝试让 Host1 连接 Host3。请特别留意按下回车后的反应速度。
# Host1 尝试连接 Host3 的计算服务
sudo ip netns exec Host1 nc -v 10.0.3.2 9999
# 现象观察:
# 在没加网络风暴前,你会瞬间看到 Connection succeeded!。
# 但是当前情况下:你可能会发现按下回车后,终端卡住了,过了好几秒(甚至更久)才显示连接成功,
# 或者需要尝试两三次才能连上。这是因为 TCP 建立连接需要的 SYN 包 或 SYN+ACK 包 在路上被丢了。
# 客户端没有收到确认,只能等待超时后重新发送 SYN 包。这个等待时间通常是指数增长的(1秒、2秒、4秒...),导致了明显的滞后感。
# 4. 卡顿的“对话” (交互测试)
# 连接建立后,我们开始输入数字,让 Host3 服务器为我们计算这个数的平方。下面为窗口的显示
# Welcome! Please enter a number:
# (输入 5 并回车)
# ... (静止 3 秒) ...
# Result: 5.0 ^ 2 = 25.0
# (输入 10 并回车)
# Result: 10.0 ^ 2 = 100.0 <-- 这次运气好,没有丢包,瞬间返回
# (输入 8 并回车)
# ... (静止 7 秒) ...
# Result: 8.0 ^ 2 = 64.0
# 现象观察: 你会发现一种诡异的“时快时慢”现象。有时结果瞬间返回,有时像死机了一样卡顿好几秒才蹦出结果
# 5. 幕后英雄 —— 原理解析
# 为什么会卡顿,而不是直接报错退出?这正是 TCP 协议伟大的地方:可靠性优于实时性。
# 当我们输入 5 并发送时,数据包经历了以下过程:
# 发送与丢失:Host1 发送了包含 5 的数据包。运气不好,碰上了那 70% 的概率,包丢了。
# 静默等待:Host1 的 TCP 协议栈启动定时器,等待 Host3 的确认(ACK)。
# 超时重传:时间到了,Host1 发现没收到 ACK,判定数据丢失。
# 它默默地(用户无感知)重新发送了数据包。
# 结果回传:Host3 收到重传包后计算出结果 25.0 并发回。如果这个结果包在回来的路上丢了,
# Host3 也会触发重传机制。
# 结论: 我们在终端看到的“卡顿几秒”,其实是 TCP 在底层为了挽救丢失的数据包,
# 正在进行一次甚至多次的 “超时 -> 重传” 循环。虽然体验变得迟钝,但数据最终准确无误地送达了。
# 6. 清理现场
sudo ip netns exec Host3 tc qdisc del dev veth3-ns root
# 实验结束后,务必删除 TC 规则,恢复网络通畅,否则后续实验会一直卡顿。
# 上述命令删除了 Host3 出口上的所有 TC 规则- 删除我们配置的TC规则:TC 的规则是持久生效的(直到重启或手动删除),因此实验结束后,务必清理我们设置的规则。首先说明如何查看当前接口配置的规则,以及如何删除规则。
# 查看当前接口配置了什么规则
sudo ip netns exec Host3 tc qdisc show dev veth3-ns
# 删除所有规则 (恢复完美网络)。即在网络命名空间 Host3 中,
# 删除网卡 veth3-ns 上的所有流量控制(tc)规则,使其恢复为默认状态。
sudo ip netns exec Host3 tc qdisc del dev veth3-ns root======================================================================== =============================== 实验介绍 =============================== ========================================================================
项目实战:基于 RTS 的无人机集群网络仿真
为了验证我们提出的 RTS (Randomized Time Slot) 无人机集群认证与分裂方案 的性能,我们基于 Linux 网络命名空间(Netns)和流量控制(TC)构建了一个高保真的网络仿真环境。本实验旨在测试该方案在复杂网络环境下的鲁棒性,包括认证耗时、吞吐量及抗干扰能力。方案整体是一个阈值签名方案,直接访问 (https://github.com/rookie-papers/RTS-UAV.git) 下载代码,具体的实现细节读者可以不用在意,按照下列介绍的方式运行即可:
一、项目简介
-
系统架构与业务流程
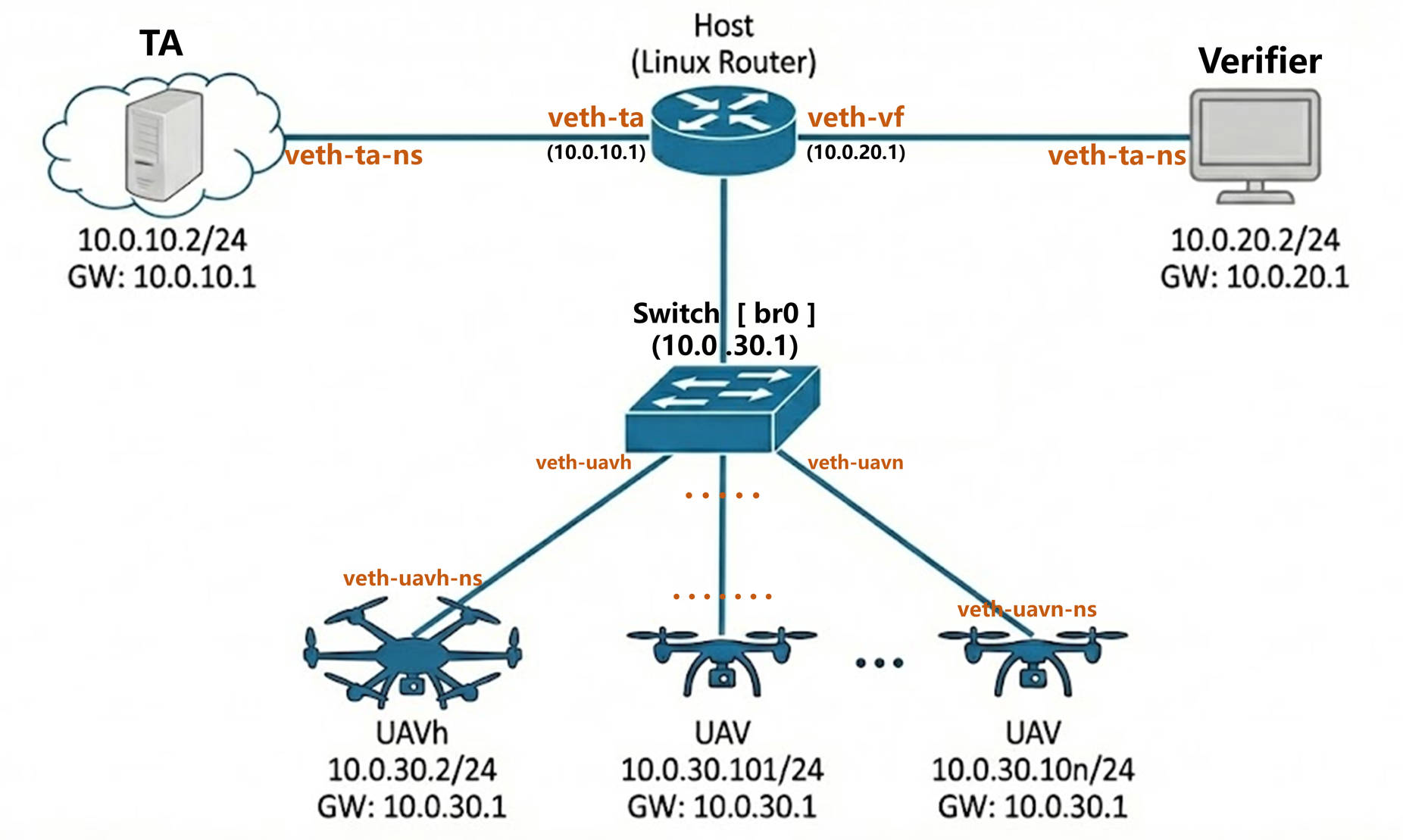
本实验构建了一个典型的“云-边-端”分布式架构。其中,云端由可信中心(TA)充当,作为整个系统的信任根,负责为所有参与实体颁发公共参数和密钥。边缘端部署验证者(Verifier),通常由地面站或基站担任,负责向无人机集群发起认证挑战,索要聚合签名并执行验证算法。终端侧则是无人机集群,由一个簇头节点(UAVh)和若干普通成员节点组成,成员负责生成各自的部分签名,而簇头则承担起汇聚任务,负责收集并聚合这些签名。整个业务流程起始于注册阶段,所有实体需先连接可信中心申请参数;随后进入聚合阶段,簇头节点并行连接所有集群成员收集签名;最后在验证阶段,验证者连接簇头获取最终的聚合证据以完成身份认证。 -
虚拟网络拓扑设计
为了高度还原真实物理环境中的网络隔离与分层通信特性,实验采用了基于 Linux 网络命名空间(Netns)的深度虚拟化拓扑设计。系统中的每一个实体——包括 TA 、验证者、簇头以及所有的普通无人机节点——都被严格封装在独立的命名空间内。使得他们都拥有彼此完全隔离的协议栈、路由表、防火墙规则及网络接口,成为了一个与现实主机功能相同的虚拟主机。 在网络互联方面,拓扑结构被精细划分为内部与外部两个层次。针对集群内部通信,实验构建了一个名为 br-swarm 的虚拟交换机(Bridge),所有的无人机节点通过虚拟以太网对(veth pair)挂载到该网桥上,共同组建了一个模拟的 Ad-hoc 局域网环境,实现了集群内部的高速互联。而对于跨域通信,例如验证者访问簇头、或各节点访问 TA 服务器的流量,则利用宿主机的内核路由转发机制进行调度,以此模拟广域网链路。整体的网络模拟拓扑结构如下:
- 项目目录及相关文件的介绍
整个 netSim 目录是一个基于 C++ 和 Linux 网络命名空间的仿真环境,主要分为代码实现和脚本控制两大部分。 在代码部分,include 和 src 目录分别包含了头文件和源文件。其中 TA、Verifier、UAVh 和 UAV 对应了实验中的四种实体:可信中心、验证者、无人机簇头和普通无人机。scheme 目录下的 RTS.cpp 则实现了核心的签名与验证方案。
在脚本部分,scripts 目录包含了控制实验流程的 Shell 脚本。build_uav_net.sh 是构建虚拟网络拓扑的核心脚本,负责创建网络命名空间。以 tc_ 开头的脚本(如 tc_bandwidth.sh, tc_latency.sh, tc_loss.sh)用于配置 Linux Traffic Control,模拟真实网络中的带宽限制、延迟和丢包。config.env 存储了 IP 和端口等环境变量,run_uavs.sh 用于批量启动程序,teardown.sh 则用于实验后的环境清理。
二、实验方法
这里我们介绍一下使用我们已经写好的代码进行实验。
2.1 虚拟环境的自动化构建与延迟测量
实验的执行过程利用了 Linux 的 Network Namespace 技术在一台机器上模拟多节点的分布式网络环境,并可以使用TC来模拟真实网络情况,具体启动实验的步骤如下:
- 首先去 GitHub.com 下载源代码
- 创建并进入 build 目录,利用 CMake 和 Make 工具编译上层目录的代码,生成 Verifier、UAV 等可执行文件,这是实验运行的基础。make之后进入build/netSim文件夹
- 构建网络拓扑。使用【sudo ./scripts/build_uav_net.sh】运行 build_uav_net.sh 脚本 。该脚本会创建多个独立的网络命名空间来隔离不同的虚拟节点,并使用 veth pair(虚拟网线)将它们按照设计好的拓扑结构连接起来。此时,节点之间的网络没有延迟和丢包。
- 配置网络环境参数。为了模拟实验假设中的网络延迟、带宽受限或特定的丢包率等现实网络状态,使用【sudo ./scripts/tc_****.sh】需要运行相应的脚本。这些脚本利用 Linux TC 工具在虚拟网卡上添加排队规则(qdisc),从而在物理层面上模拟出广域网或无线链路的通信特征。
- 依次启动实验节点。【注意:配置文件中默认的无人机总数和阈值都是64,即(t,n)=(64,64)】
- 使用【sudo ip netns exec TA ./TA_netSim】启动TA。
- 使用【sudo ./scripts/run_uavs.sh】执行 run_uavs.sh 脚本批量启动无人机
- 使用【sudo ip netns exec UAVh ./UAVh_netSim】启动无人机簇头。
- 使用【sudo ip netns exec Verifier ./Verifier_netSim】启动验证者,验证者启动后,会访问簇头无人机,簇头无人机并行向所有无人机索要部分签名。然后将受到的部分签名进行转换,发送给验证者,验证者验证签名的正确性,并自动测试整个过程的耗时。
- 最后是环境清理。实验数据收集完毕后,运行 teardown.sh 脚本删除所有的命名空间和虚拟网卡,恢复宿主机的网络设置,防止对后续实验造成干扰。
2.2 关于无人机簇头节点 UAVh 串行收集签名与并行收集签名的对比
-
串行请求模式 (Serial Mode)
在串行模式下,簇头 UAVh 采用同步阻塞的方式与成员无人机通信。它首先向第一架无人机发送签名请求,必须完全等待接收到该无人机的回复后,才开始处理第二架无人机的请求。 这种机制的逻辑实现非常简单,且不会在瞬间产生网络拥塞。然而,其最大的缺点是时间开销随节点数量线性增长。在实验设置的 50ms 网络延迟环境下,一次请求-响应周期需要 100ms。如果有 10 架无人机,串行收集将耗费 1000ms(1秒),这对于实时性要求高的系统是无法接受的。 -
并行请求模式 (Parallel Mode)
在并行模式下,UAVh 利用多线程或异步 I/O 技术同时处理多个连接。簇头会在极短的时间内向所有成员无人机广播或并发发送签名请求,而无需等待任何回复。发送完毕后,UAVh 统一监听端口,接收陆续到达的签名数据。 这种机制大大提高了效率,其总耗时不再是所有节点耗时的总和,而是取决于响应最慢的那一个节点(短板效应)。在理想带宽下,无论有多少架无人机,并行收集的总耗时都维持在单次交互的时间水平(如实验中的 100ms 左右)。这能够最大程度地利用网络带宽,满足实时签名的需求。
三、实验结果分析
通过上述分析可知,在实际应用场景中,无人机签名的收集过程是并发进行的。在网络带宽充足的条件下,无人机数量的增加对实验结果的影响甚微。 为了量化网络环境对认证效率的影响,我们首先测定了基准数据:在门限值为 64 且无额外网络延迟的情况下,该认证方案的纯计算与处理耗时约为 230ms。 随后,我们在仿真环境中引入网络延迟。我们为 Verifier(验证者)和 UAVh(簇头)的出口流量(Egress)各设置了 50ms 的物理延迟。需要特别说明的是,由于 Linux TC(Traffic Control)仅作用于流出流量,因此在拓扑内部,UAV 返回给 UAVh 的信息流不受此限制,延迟接近 0ms。在此配置下运行实验,观测到的完整认证耗时约为 530ms。
相较于基准值(230ms),网络传输引入了约 300ms 的额外延迟。针对“设置了 50ms 链路延迟,为何导致 300ms 总时延”这一现象,分析如下: 这一时间差异主要归因于底层通信协议的交互机制。实验中的 WebSocket 通信基于 TCP 协议,建立连接需要经过握手过程。结合实验抓包数据,我们将这 300ms 的网络时延拆解为以下三个关键交互阶段,具体流程如下图所示:
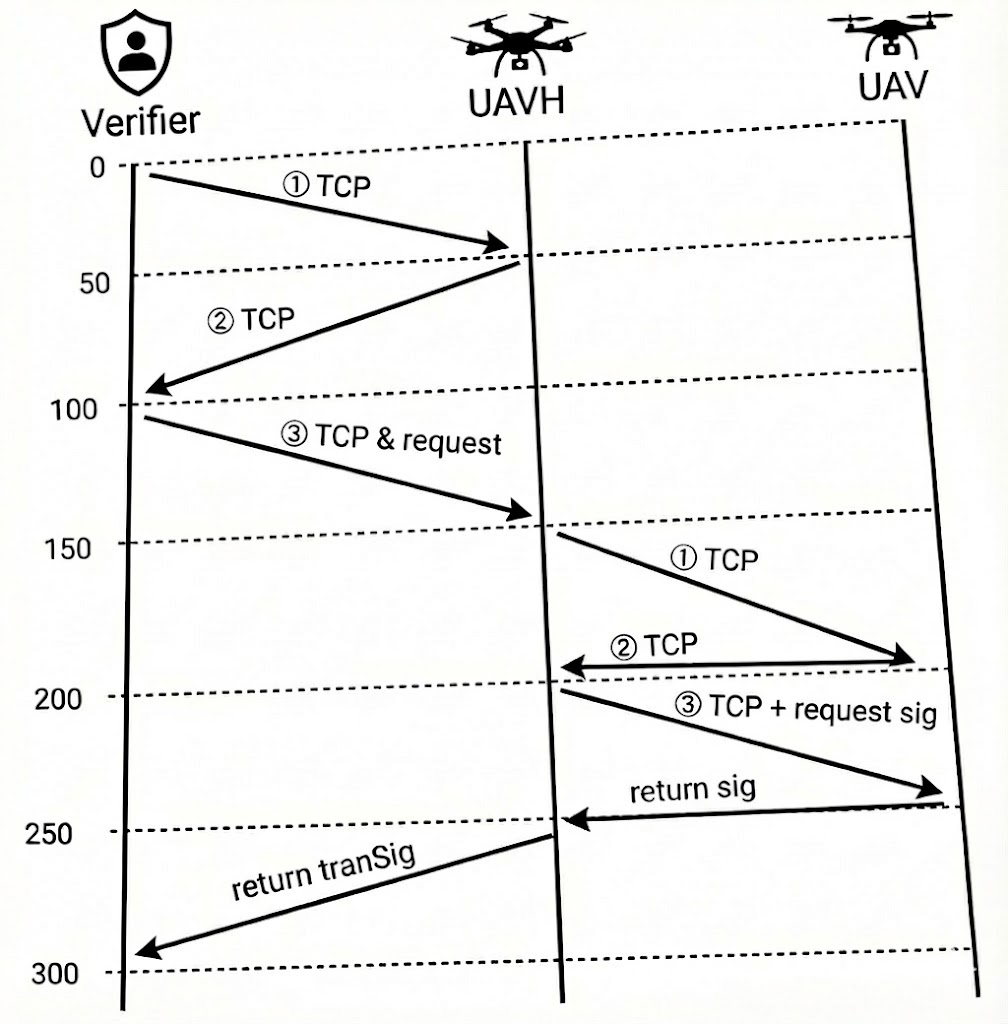
时序拆解分析
结合实验中的四个实体及核心交互流程,我们将这 $300\text{ms}$ 的时延具体分布解析如下:
-
第一阶段:外部链路建立与请求下发 ($0 \sim 150\text{ms}$)
此阶段发生在 Verifier $\leftrightarrow$ UAVh 之间,主要由 TCP 三次握手及请求的“捎带”传输构成:- $0 \sim 50\text{ms}$ (SYN): Verifier 向集群入口 UAVh 发起连接,发送 TCP SYN 包。耗时 $50\text{ms}$。
- $50 \sim 100\text{ms}$ (SYN-ACK): UAVh 收到请求后,回复 SYN-ACK 确认包。耗时 $50\text{ms}$。
- $100 \sim 150\text{ms}$ (ACK & Request): Verifier 在发送第三次握手 (ACK) 的同时,将具体的业务请求一同发送给 UAVh。至 $150\text{ms}$ 时刻,UAVh 已成功建立连接并收到了认证请求。
-
第二阶段:群组内部中继与签名采集 ($150 \sim 250\text{ms}$)
此阶段发生在 UAVh $\leftrightarrow$ UAV。得益于群组内部的高速互联特性以及 TC 仅限制出口流量的设定,回程时延被极大压缩:- $150 \sim 200\text{ms}$ (SYN): UAVh 作为簇头,向 UAV 转发连接请求(SYN)。耗时 $50\text{ms}$。
- $200\text{ms}$ (ACK): 由于UAV 没有TC延迟,因此回复 (SYN-ACK) 给 UAVh 的耗时接近 $0\text{ms}$)。
- $200 \sim 250\text{ms}$ (Sign Request): UAVh 随即向 UAV 发送部分签名请求。耗时 $50\text{ms}$。
- $250\text{ms}$ (Sign Return): UAV 完成签名计算,并立即将签名数据回传给 UAVh。
-
第三阶段:结果聚合与回传 ($250 \sim 300\text{ms}$)
- $250 \sim 300\text{ms}$: UAVh 在 $250\text{ms}$ 收到成员签名后,进行转换与聚合,并通过外部链路将最终的 转换后的签名回传给 Verifier。耗时 $50\text{ms}$,最后验证者验证签名,完成身份认证。
综上所述,虽然单向物理链路延迟仅为 $50\text{ms}$,但由于认证过程涉及 TCP 连接建立、跨网段中继以及数据回传等多次往返交互,系统的总时延却增加了整整 300ms(即 $6 \times 50\text{ms}$)。
下面给出一个文字版的图示:
Verifier UAVH (Cluster Head) UAV
| | |
0 +---- ① TCP SYN ----------------->| |
| (50ms delay) | |
| | |
50 |<--- ② TCP [S.] (SYN-ACK) -------+ |
| (50ms delay) | |
| | |
100 +---- ③ TCP + Request ----------->| |
| (Piggybacking / 50ms) | |
| | |
150 | +---- ① TCP SYN ----------------->|
| | (50ms delay) |
| | |
200 | |<--- ② TCP [S.] (SYN-ACK) -------+
| | (Internal / ~0ms) |
| | |
200 | +---- ③ TCP + Request Sig ------->|
| | (50ms delay) |
| | |
250 | |<--- Return Signature -----------+
| | (Internal / ~0ms) |
| | |
250 |<--- Return TransSig -------------+ |
| (50ms delay) | |
| | |
300 + (Finish) | |
| | |
======================================================================== =============================== 实验介绍 =============================== ========================================================================
六、常用命令总结
Linux 网络管理目前主要依赖 iproute2 工具集,其中的 ip 命令是最核心的入口。它的命令结构非常统一,遵循 ip [对象] [操作] [参数] 的逻辑。 在我们之前的实验中,主要涉及了五个核心对象:
- netns:操作隔离房间(命名空间)。
- link:操作网卡、网线和交换机(设备层)。
- addr:操作门牌号(IP地址层)。
- route:操作地图(路由表)。
- tc:操作红绿灯和限速牌(流量控制层)。
理解了这五个对象的职能,就能掌握绝大多数网络模拟的指令。以下是详细解析:
# --- 1. ip netns:网络命名空间管理 ---
# ip netns add [名称]
# 创建一个新的网络命名空间。
# 例子:创建一个名为 Host1 的隔离环境。
sudo ip netns add Host1
# ip netns list
# 列出当前系统中所有的网络命名空间。
sudo ip netns list
# ip netns del [名称]
# 删除指定的命名空间。注意,该空间内的虚拟网卡、路由表等配置也会一并清除。
sudo ip netns del Host1
# ip netns exec [名称] [命令]
# 在指定的命名空间内部执行命令。这是进入虚拟环境的“传送门”。
# 例子:在 Host1 内部执行 ip addr 命令查看 IP。
sudo ip netns exec Host1 ip addr
# --- 2. ip link:网络接口与网桥管理 ---
# ip link add [设备名] type veth peer name [对端设备名]
# 创建一对 Veth Pair(虚拟网线)。
# 例子:创建一头叫 veth1,另一头叫 veth1-ns 的网线。
sudo ip link add veth1 type veth peer name veth1-ns
# ip link add name [网桥名] type bridge
# 创建一个虚拟网桥(交换机)。
# 例子:创建一个名为 br0 的网桥,用于连接多个网段。
sudo ip link add name br0 type bridge
# ip link set [设备名] netns [命名空间名]
# 将指定的网络接口“移动”到某个命名空间中。
# 例子:把网线的一头 veth1-ns 扔进 Host1 房间里。
sudo ip link set veth1-ns netns Host1
# ip link set [设备名] master [网桥名]
# 将网卡插到网桥(交换机)上。
# 例子:将 veth1 接口连接到 br0 网桥上,使其成为交换机的一个端口。
sudo ip link set veth1 master br0
# ip link set [设备名] up
# 启动网络接口。接口创建后默认是 DOWN(关闭)状态,必须手动启动。
# 注意:网桥 br0 创建后也需要 set up 才能工作。
sudo ip link set veth0 up
sudo ip link set br0 up
# ip link delete [设备名]
# 删除网络接口。
# 如果删除 veth 的一头,另一头会自动消失;如果删除 br0,连接在上面的网卡会断开连接。
sudo ip link delete veth0
sudo ip link delete br0
# --- 3. ip addr:IP 地址管理 ---
# ip addr add [IP地址/掩码] dev [设备名]
# 给指定的网卡配置 IP 地址。
# 例子:给 veth0 配置 10.0.0.1 的 IP,子网掩码为 24位。
sudo ip addr add 10.0.0.1/24 dev veth0
# ip -br addr
# 以精简模式(Brief)查看当前所有的 IP 地址信息,忽略多余的细节。
# 这是一个非常实用的查看命令。
ip -br addr
# --- 4. ip route:路由表管理 ---
# ip route add default via [网关IP]
# 添加默认路由。这是告诉主机:“如果你不知道去哪里,就把包发给这个 IP”。
# 例子:Host1 想上网,必须把包发给宿主机(网关 10.0.1.1)。
sudo ip route add default via 10.0.1.1
# ip route list
# 查看当前的路由表(地图)。
# 检查是否包含 default via ... 行,以及直连路由是否正确。
sudo ip route list
# --- 5. 其他关键系统设置 ---
# sysctl -w net.ipv4.ip_forward=1
# 开启 Linux 内核的 IP 转发功能。
# 只有开启了这个开关,宿主机才能从“普通电脑”变身为“路由器”,
# 允许数据包从一张网卡进入,从另一张网卡出去。
sudo sysctl -w net.ipv4.ip_forward=1
# --- 6. tc:流量控制与网络仿真 (Traffic Control) ---
# 注意:tc 规则通常施加在发送端(出口 Egress)的网卡上。
# tc qdisc add dev [设备名] root netem [参数]
# 为指定设备添加一个根队列规则 (qdisc),使用 netem (网络仿真) 模块。
# 例子:给 veth3-ns 添加 100ms 的延迟。
sudo ip netns exec Host3 tc qdisc add dev veth3-ns root netem delay 100ms
# tc qdisc change ...
# 修改已有的规则。如果你已经 add 过了,再次修改参数必须用 change。
# 例子:将延迟改为 100ms,并带有 20ms 的随机抖动 (Jitter)。
sudo ip netns exec Host3 tc qdisc change dev veth3-ns root netem delay 100ms 20ms
# netem loss [百分比]
# 模拟丢包。
# 例子:模拟 50% 的极高丢包率。
sudo ip netns exec Host3 tc qdisc change dev veth3-ns root netem loss 50%
# netem reorder [百分比] [相关性] gap [数量]
# 模拟包乱序。
# 例子:每隔 3 个包,第 4 个包就立即发送(不延迟),造成乱序。
sudo ip netns exec Host3 tc qdisc change dev veth3-ns root netem delay 10ms reorder 100% gap 3
# tbf rate [带宽] burst [缓冲] latency [延迟]
# 使用令牌桶过滤器 (Token Bucket Filter) 进行带宽限制。
# 例子:限制带宽为 1Mbit/s。
sudo ip netns exec Host3 tc qdisc change dev veth3-ns root tbf rate 1mbit burst 32kbit latency 400ms
# tc qdisc show dev [设备名]
# 查看当前接口上配置了哪些流量控制规则。
sudo ip netns exec Host3 tc qdisc show dev veth3-ns
# tc qdisc del dev [设备名] root
# 删除设备上的所有根队列规则,恢复网络为默认的“完美状态”。
# 实验结束后务必执行此步骤。
sudo ip netns exec Host3 tc qdisc del dev veth3-ns root